Writing
Learning in public
Shipping what I learn.
Latest posts 6 posts
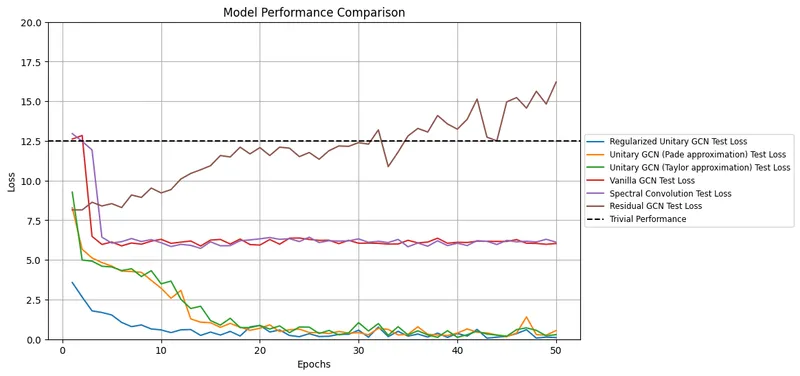
Extending unitary convolutions for learning on graphs
Reducing oversmoothing with unitary graph convolutions.
Still lost in the middle
Why models forget the middle of a prompt.

Even more efficient finetuning
Fewer trainable parameters, better performance.
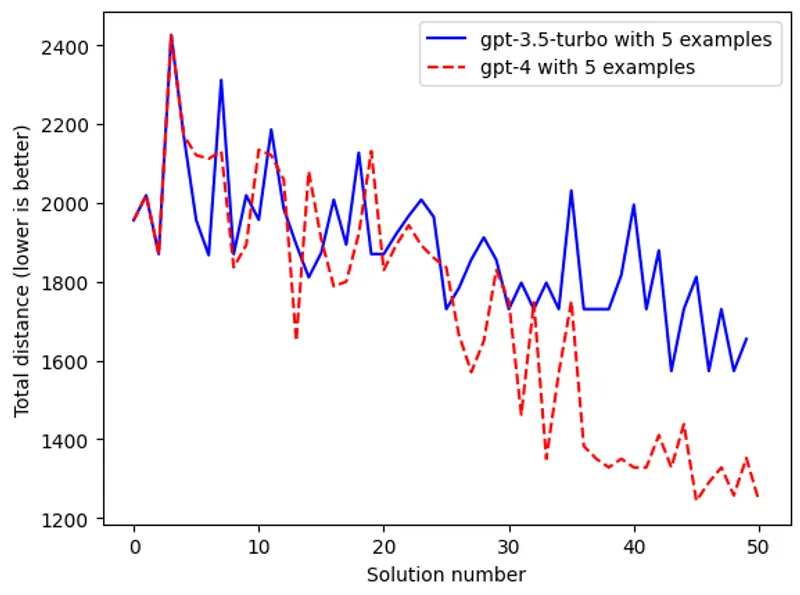
Optimization by prompting
Prompting as a lightweight optimization tool.
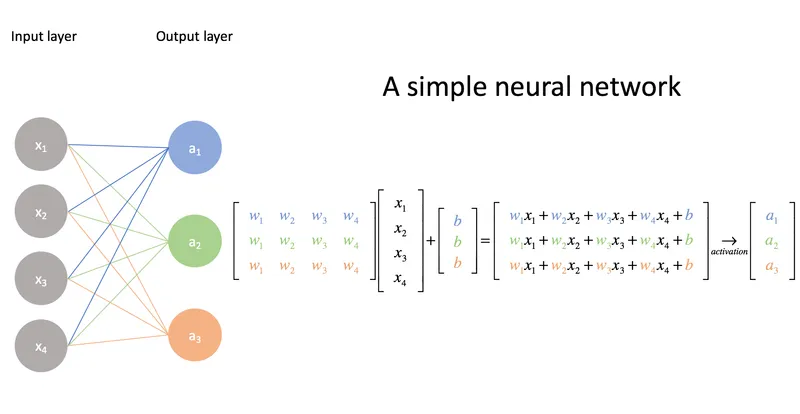
More efficient finetuning
Low-rank adapters for fast, local finetuning.

Transformers: unpacking the buzzword
What are transformers?